Finding all the URLs on a website is one of the most vital tasks in any web-scraping workflow. In this tutorial, we'll walk through multiple ways to find all URLs on a domain: from using Google search tricks, to exploring pro-level SEO tools like ScreamingFrog, and even crafting a Python script to pull URLs at scale from a sitemap. Don't worry, we've got you covered on building a clean list of URLs to scrape (and as a bonus, we'll even show you how to grab some data along the way).

Why get all URLs from a website?
Ever wondered why finding all the URLs on a website might be a good idea? Here are some reasons why this task can be super handy, especially when you're looking for the best way to find all URLs on a website or simply want to find all pages on a website in a clean, structured way:
- Scrape all the website's content: before analyzing anything, you need to know what pages exist — that's where the URL hunt kicks in.
- Fixing broken links: broken links hurt UX and SEO, so spotting and fixing them is essential.
- Making sure Google notices you: slow or non-mobile-friendly pages can tank rankings; a full URL sweep helps surface issues.
- Catching hidden pages: duplicate content, poor internal linking, or setup quirks can cause Google to miss pages — regular checks help.
- Finding pages Google shouldn't see: staging pages, admin paths, or unfinished drafts can accidentally leak into search results.
- Refreshing outdated content: knowing every page makes content updates and SEO planning way easier.
- Improving site navigation: discovering orphan pages helps clean up structure and boost credibility.
- Spying on competitors: mapping a competitor's full site can reveal their priorities, funnels, and content strategy.
- Prepping for a website redesign: having a full URL inventory keeps migrations smooth.
- AI-assisted site auditing: modern workflows use AI tools to automatically scan, classify, and analyze entire websites.
- Example: the AI web scraper can streamline discovery and auditing.
There are various ways to uncover every page on a website, each with its own advantages and challenges. Let's explore how to tackle this task in an efficient way.
How to find all webpages on a website?
In this section, we'll explore some effective ways to find all URLs on a domain. Detailed instructions will follow, helping you master each method.
1. Google Search
One of the simplest methods is to use Google Search. Just type in a specific search query to see all pages on a website. However, remember that this approach might not catch everything as some pages could be missing, and outdated ones may still show up.
Use Google Search operators
To go beyond the basic site: query, you can combine additional Google operators to discover even more URLs. This helps when you're learning how to find website links or how to find links to a website in a more targeted way. These operators let you uncover hidden sections, file types, or specific topics within a domain.
Below is a quick reference table of the most useful operators:
| Operator | Example | What It Helps You Do |
|---|---|---|
site: | site:example.com | List all indexed pages from a domain. |
inurl: | site:example.com inurl:blog | Find pages with specific words in the URL. Great for filtering sections or topics. |
intitle: | site:example.com intitle:pricing | Discover pages by title keywords — helpful for spotting landing pages or key content hubs. |
filetype: | site:example.com filetype:pdf | Surface downloadable files such as PDFs, docs, or spreadsheets. |
| Combine operators | site:example.com inurl:2024 intitle:report | Stack operators to narrow results to hyper-specific segments. |
Using these operators together gives you a sharpened view of a website's structure, revealing pockets of content that normal browsing or crawling might miss.
Using ScrapingBee to scrape Google search results
When it comes to scraping Google search results, things can get a bit tricky. Copying and pasting each link by hand can eat up a lot of time, and Google isn't exactly fond of automated scraping. That's where ScrapingBee steps in. With its simple Google request builder, you can pull structured search data without wrestling with rate limits or CAPTCHAs. If you ever need a more advanced setup, the dedicated Google Search API is also available.
If you haven't already done so, register for free and then proceed to the Google API Request Builder:

Pop your search query into the Search field and press Try it:
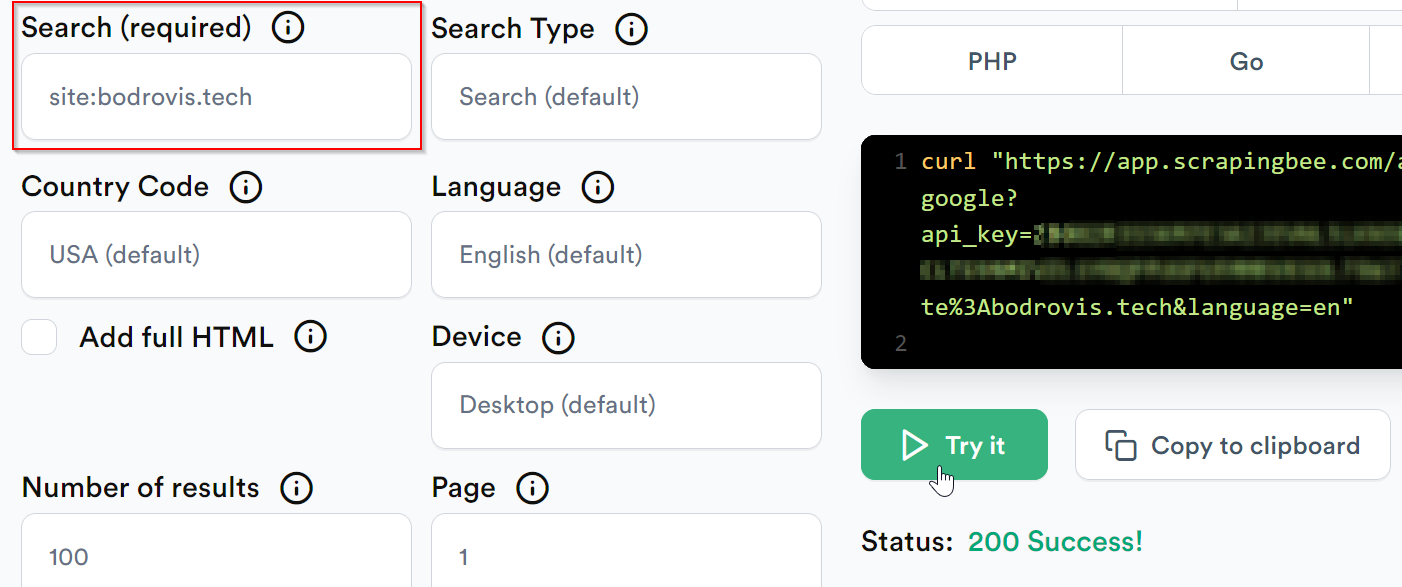
You'll receive your results in a clean JSON format. Here's an example with the relevant fields — notice the url keys that contain the actual page links:
"organic_results": [
{
"url": "https://bodrovis.tech/",
"displayed_url": "https://bodrovis.tech"
},
{
"url": "https://bodrovis.tech/en/teaching",
"displayed_url": "https://bodrovis.tech › teaching"
},
{
"url": "https://bodrovis.tech/ru/blog",
"displayed_url": "https://bodrovis.tech › blog"
}
]
Now you can simply download this JSON document and use it for your needs. Please refer to my other tutorial to learn more about scraping Google search results.
2. Sitemap and robots.txt
For those who don't mind getting a bit more technical, checking a website's sitemap and robots.txt file can reveal a ton of useful information. Both files are usually accessible by visiting:
https://example.com/sitemap.xmlhttps://example.com/robots.txt
A sitemap often lists every important URL the site wants search engines to see, while robots.txt may link to additional sitemaps or show which sections are restricted. When these files are configured correctly, this is one of the fastest ways to map a site.
However, not every website plays nice. Some sitemaps are hidden behind redirects, rate limits, or JavaScript-generated responses. Others are intentionally blocked or incomplete. If you run into a protected or partially inaccessible sitemap, you can use ScrapingBee's web scraping API with JavaScript rendering to fetch those files reliably and bypass common restrictions.
Finding all URLs with sitemaps and robots.txt
This approach is a bit more technical but can give you more detailed results. We'll dive into how sitemaps and robots.txt files can help you uncover all the URLs of a website.
Sitemaps
Webmasters use XML files known as "sitemaps" to help search engines better understand and index their websites. Think of sitemaps as roadmaps that provide valuable insights into the website's layout and content.
Here's what a standard sitemap looks like:
<urlset xsi:schemaLocation="...">
<url>
<loc>https://example.com</loc>
<lastmod>2024-02-18T13:13:49+00:00</lastmod>
<changefreq>weekly</changefreq>
<priority>0.5</priority>
</url>
<url>
<loc>https://example.com/some/path</loc>
<lastmod>2024-02-18T13:13:49+00:00</lastmod>
<changefreq>weekly</changefreq>
<priority>0.5</priority>
</url>
</urlset>
This XML structure shows two URLs under the url tag, with each loc tag revealing the URL's location. Additional details like the last modification date and frequency of change are mainly for search engines.
For smaller sitemaps, you can manually copy the URLs from each loc tag. To simplify the process for larger sitemaps, consider using an online tool to convert XML to a more manageable format like CSV.
Be aware that large websites may use multiple sitemaps. Often, there's a main sitemap that points to other, more specific sitemaps:
<sitemapindex xsi:schemaLocation="...">
<sitemap>
<loc>
https://example.com/sitemaps/english.xml
</loc>
<lastmod>2024-02-18T13:13:49+00:00</lastmod>
</sitemap>
<sitemap>
<loc>
https://example.com/sitemaps/french.xml
</loc>
<lastmod>2024-02-18T13:13:50+00:00</lastmod>
</sitemap>
</sitemapindex>
If you study this file for a few moments, it becomes obvious that the website has two sitemaps: one for English language, and one for French. Then you can simply visit each location to view the corresponding contents.
How to find sitemaps?
Not sure where to find a sitemap? Try checking /sitemap.xml on the website, like https://example.com/sitemap.xml. The robots.txt file, discussed next, often includes a sitemap link.
Other common sitemap locations include:
/sitemap.xml.gz/sitemap_index.xml/sitemap_index.xml.gz/sitemap.php/sitemapindex.xml/sitemap.gz/sitemapindex.xml
Another effective method involves leveraging our old friend Google. Simply navigate to the Google search bar and enter: site:DOMAIN filetype:xml, remembering to replace DOMAIN with your actual website's domain. This neat trick is designed to unearth a wealth of indexed XML files associated with your site, notably including those all-important sitemaps.
Keep in mind, if your website is particularly rich in XML files, you might find yourself doing a bit of extra legwork to filter through everything. But not to worry—consider it a small, intriguing part of the journey!
Using robots.txt
robots.txt is yet another file created for search engines. Typically it says where the sitemap is located, which pages should be indexed, and which are disallowed for indexing. According to current standards, this file should be available under the /robots.txt path.
Here's an example of the robots.txt file:
User-agent: *
Sitemap: https://example.com/sitemap.xml
Disallow: /login
Disallow: /internal
Disallow: /dashboard
Disallow: /admin
Host: example.com.
In the example above we can see where the sitemap is located. Also there are a few routes that have been disallowed for indexing which means that they are indeed present on the site.
3. SEO spider tools
If you're looking for a straightforward, point-and-click solution, SEO spider tools are a solid option. They crawl a website much like a search engine would, collecting URLs, internal links, status codes, metadata, and more. The downside? Many of the more powerful features sit behind paid tiers, and free plans often come with crawl limits.
Here's a quick comparison of commonly used SEO crawlers:
| Tool | Free Tier | Strengths | Limitations |
|---|---|---|---|
| Screaming Frog | Crawls up to 500 URLs | Extremely detailed, desktop-based, highly configurable | Free version capped at 500 URLs, advanced features require a license |
| XML-Sitemaps.com | Basic online crawler | Simple, generates downloadable sitemaps | Limited crawl depth and features unless upgraded |
| Ahrefs Free Crawler | Limited access | Great link insights, strong indexing data | Full crawling tools require paid Ahrefs subscription |
| Semrush Site Audit | Limited credits | Excellent UI, strong SEO diagnostics | Daily crawl limits; deeper reports require paid plan |
While these tools are convenient, they can become restrictive if you need to crawl large sites, automate the workflow, or integrate results into code. For high-scale programmatic crawling, consider using an API built specifically for web data extraction.
Use ScreamingFrog to crawl the website
Now let's see how to use a SEO spider and find all the website pages. We'll take advantage of the tool called ScreamingFrog. Ready to give it a whirl? Grab it from their official website to get started. They offer a free version that's perfect for smaller sites, allowing you to uncover up to 500 pages.
Once downloaded, launch the tool (in crawl mode), pop your website's URL into the top text field, and hit Start:

Give it a little time—especially for those more intricate websites—and soon you'll have a complete list of URLs right before your eyes:
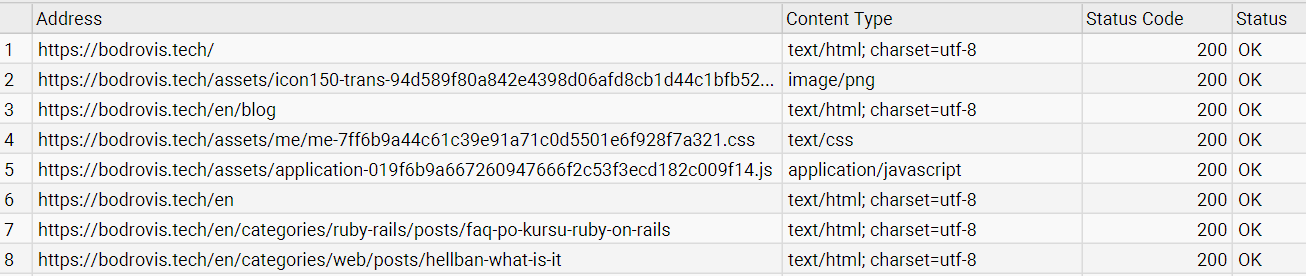
It lists everything by default, including images, JS, and CSS files. If you're only after the main HTML pages, just tweak the Filter option to narrow it down:
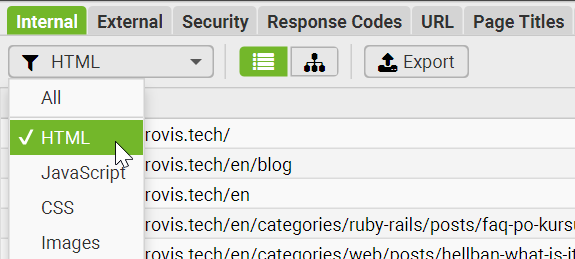
Also use tabs on top to choose the data to display. For example, by using this tool you can easily find broken links on your website.
Getting started with this tool is a breeze. But, be aware that sometimes a site might block your efforts for various reasons. If that happens, there are a few tricks you can try, like changing the user agent or reducing the number of threads in use. Head over to the Configuration menu to adjust these settings:
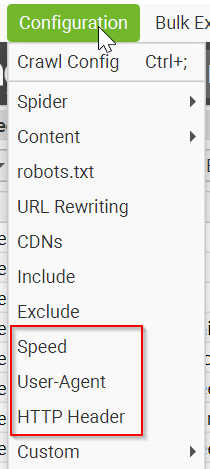
You'll mostly be interested in tweaking the Speed, User-Agent, and HTTP Header settings. Although, keep in mind, some of these advanced features are part of the paid version. Setting your user agent to "Googlebot (Smart Phone)" can often help, but the right speed setting might take some experimentation to get just right, as different sites have their own ways of detecting and blocking scrapers.
Also in the "Crawl Config" it's worth unticking "External links" as we only want the links on the target website.
4. Custom scripting
For those with specific needs and a bit of coding knowledge, creating a custom script might be the best route. This is the most involved method but allows for customization and potentially the most thorough results. If you have the time and skills, a DIY script can be a rewarding project that perfectly fits your requirements.
Each of these methods offers a different balance of ease, accuracy, and depth of information. Whether you prefer a quick overview or a deep dive, there's an approach here to suit your needs.
Create a script to find all URLs on a domain
In this section, I'll guide you through crafting a custom Python 3 script to get all URLs from a website by scraping its sitemap and then extracting some data from the pages.
Here we'll demo a Walmart scraper which was created by our legendary Support Engineer, Sahil Sunny, who is a master at helping people scrape anything and everything from across the internet, and we'll be walking you through it today. 🚀🌟
Preparing the project
First off, let's kickstart a new project using Poetry:
poetry new link_finder
Now, beef up your project's dependencies by running the following command:
poetry add python-dotenv numpy pandas tqdm scrapingbee xmltodict
If you don't use Poetry, simply install these libraries with pip.
Next let's create the src/link_finder/main.py file and import the necessary dependencies:
import os
import json
import glob
import logging
import time
import numpy as np
import pandas as pd
import xmltodict
from tqdm import tqdm
from concurrent.futures import ThreadPoolExecutor, as_completed
from scrapingbee import ScrapingBeeClient
from urllib.parse import urlparse
from dotenv import load_dotenv
Project configuration
Let's also create an .env file in the project root and paste your ScrapingBee API key inside. We'll use ScrapingBee to add a bit of AI magic that will greatly help with the data processing:
SCRAPINGBEE_API_KEY=YOUR_API_KEY
🤖 To follow along with this tutorial and run this script, grab your Free 1,000 scraping credits and API Key
Load your environment variables in the script:
load_dotenv()
Create all the necessary constants:
SITEMAP_URL = "https://www.walmart.com/sitemap_category.xml"
SITE_NAME = "walmart"
SB_API_KEY = os.getenv("SCRAPINGBEE_API_KEY")
CONCURRENCY_LIMIT = 5 # Adjust as needed
DATA_DIR = "product-data/data"
LOG_FILE = "product-data/logs.csv"
CSV_OUTPUT = "product-data/data.csv"
In this example we're going to scrape Walmart website but of course you can provide any other URL. We'll store all the found URLs, product information, and the log file.
Now let's proceed to the main part of the script.
Fetching sitemap URLs
First, we need a function to fetch product URLs from Walmart's sitemap.
def fetch_sitemap_urls():
"""Fetch sitemap URLs and save them to a file."""
logging.info("Fetching sitemap content.")
response = client.get(SITEMAP_URL, params={'render_js': False})
sitemap_data = xmltodict.parse(response.text)
if 'urlset' not in sitemap_data or 'url' not in sitemap_data['urlset']:
logging.error("Invalid or empty sitemap structure.")
return []
urls = [urlobj['loc'] for urlobj in sitemap_data['urlset']['url']]
urls_file = f'{SITE_NAME}_urls.txt'
with open(urls_file, 'w') as f:
f.write('\n'.join(urls))
logging.info(f"Sitemap URLs saved to {urls_file}.")
return urls
This function:
- Fetches the sitemap XML from Walmart.
- Parses the XML to extract product URLs.
- Saves the URLs to a file for reference.
- Returns the extracted URLs for further processing.
Extracting a clean slug from URLs
Next, we need a helper function to extract a clean and unique identifier (slug) from a product URL.
from urllib.parse import urlparse
def extract_slug(url):
"""Extract a safe slug from a URL using urlparse."""
parsed = urlparse(url)
slug = parsed.path.rstrip('/').split('/')[-1]
return slug if slug else "default_slug"
This function:
- Uses urlparse to break down the URL structure.
- Extracts the last part of the path (which is usually the product identifier).
- Returns a default slug if extraction fails.
Scraping product data
Now, let's write the core function that scrapes product data from Walmart.
def scrape_product(url):
"""Scrape a product page, save its JSON data, and return a status log."""
start_time = time.time()
try:
response = client.get(
url,
params={
'premium_proxy': True,
'country_code': 'us',
'render_js': False,
'ai_extract_rules': json.dumps({
"name": {"description": "Product Name", "type": "list"},
"description": {"description": "Product Description", "type": "list"},
"original_price": {"description": "Original Price", "type": "list"},
"offer_price": {"description": "Discounted Price", "type": "list"},
"link": {"description": "Product URL", "type": "list"}
})
}
)
status_code = response.status_code
resolved_url = response.headers.get('spb-resolved-url', url)
if status_code == 200:
try:
cleaned_text = response.text.strip().replace("```json", "").replace("```", "")
cleaned_data = json.loads(cleaned_text)
slug = extract_slug(url)
with open(f'{DATA_DIR}/{slug}.json', 'w') as f:
json.dump(cleaned_data, f, indent=2)
return {'url': url, 'status_code': status_code, 'resolved_url': resolved_url, 'message': 'Success'}
except json.JSONDecodeError as e:
logging.error(f"JSON Parsing Error for {url}: {e}. Response snippet: {response.text[:500]}")
return {'url': url, 'status_code': status_code, 'resolved_url': resolved_url, 'message': 'JSON Parsing Error'}
return {'url': url, 'status_code': status_code, 'resolved_url': resolved_url, 'message': 'Scraping Failed'}
except Exception as e:
return {'url': url, 'status_code': 'Error', 'resolved_url': '', 'message': str(e)}
finally:
elapsed = time.time() - start_time
iteration_times.append(elapsed)
if len(iteration_times) > 100: # Limit list size
iteration_times.pop(0)
This function:
Sends a request to Walmart with ScrapingBee
Instead of a simple HTTP request, we use ScrapingBee's proxy network to avoid detection and ensure stable access to Walmart's data. The request is customized with parameters like location targeting (country_code: "us") and proxy options.Uses AI extraction to retrieve structured product data (name, price, description, etc.)
We don't need to manually write parsing logic. Instead, we define an AI extraction rule that tells ScrapingBee what information to look for (e.g.,"name","original_price","offer_price"). The AI processes the page and returns clean JSON data, saving us from writing custom web-scraping logic.Parses and cleans the JSON response
Since the AI output might contain formatting artifacts, we clean the response before parsing it. This includes removing unnecessary markdown-like formatting (````json` blocks).Saves the data to a file for later use
The extracted product details are stored as a JSON file using a unique identifier from the URL. This ensures we can process the data later or re-run the script without losing progress.Returns a log entry containing the scraping status
Each function call returns a structured log entry that includes:- The original URL
- The resolved URL (in case of redirects)
- The HTTP status code
- A message indicating whether the scraping succeeded or failed
Running scraping tasks concurrently
Since Walmart has thousands of product pages, we need to scrape multiple pages at the same time.
def execute_scraping(urls):
"""Run scraping tasks concurrently and update progress."""
logging.info("Starting concurrent scraping.")
log_entries.clear()
with ThreadPoolExecutor(max_workers=CONCURRENCY_LIMIT) as executor:
futures = {executor.submit(scrape_product, url): url for url in urls[:100]}
with tqdm(total=len(futures), desc='Scraping Progress', dynamic_ncols=True) as progress_bar:
for future in as_completed(futures):
result = future.result()
log_entries.append(result)
median_time = np.median(iteration_times) if iteration_times else 0
progress_bar.set_postfix({'Median Iter/sec': f"{(1 / median_time) if median_time > 0 else 0:.2f}"})
progress_bar.update(1)
This function:
- Uses
ThreadPoolExecutorto scrape multiple URLs at once. - Limits concurrency to prevent getting blocked.
- Tracks progress using tqdm.
- Stores scraping logs in a list.
Processing scraped data into a csv file
Once all JSON files are collected, we need to combine them into a structured CSV file.
def process_scraped_data():
"""Combine scraped JSON files into a CSV and log any errors."""
json_files = glob.glob(f"{DATA_DIR}/*.json")
df_list, error_files = [], []
logging.info("Processing scraped data into CSV.")
for file in json_files:
try:
with open(file, "r", encoding="utf-8") as f:
data = json.load(f)
if isinstance(data, list):
df_list.append(pd.DataFrame(data))
elif isinstance(data, dict):
df_list.append(pd.DataFrame([data]))
else:
raise ValueError("Unexpected JSON format")
except Exception as e:
logging.error(f"Error reading {file}: {e}")
error_files.append(file)
if df_list:
final_df = pd.concat(df_list, ignore_index=True)
final_df.to_csv(CSV_OUTPUT, index=False, encoding="utf-8")
logging.info(f"Data successfully saved to '{CSV_OUTPUT}'.")
else:
logging.warning("No valid data found to save.")
if error_files:
logging.warning("The following files caused errors:")
for err_file in error_files:
logging.warning(f" - {err_file}")
This function:
- Reads all JSON files from the data directory.
- Converts the JSON structure into a pandas DataFrame.
- Saves the data into a CSV file.
- Logs any errors encountered during processing.
Saving logs
Lastly, let's write a function to save the scraping logs for debugging.
def save_logs():
"""Save scraping logs to a CSV file."""
logs_df = pd.DataFrame(log_entries)
logs_df.to_csv(LOG_FILE, index=False, encoding="utf-8")
logging.info(f"Logs saved to '{LOG_FILE}'.")
This function:
- Converts log entries into a CSV file.
- Ensures that we have a record of which pages were successfully scraped.
Full Python script to find all URLs on a domain's website
Now, let's assemble everything into a complete script.
import os
import json
import glob
import logging
import time
import numpy as np
import pandas as pd
import xmltodict
from tqdm import tqdm
from concurrent.futures import ThreadPoolExecutor, as_completed
from scrapingbee import ScrapingBeeClient
from urllib.parse import urlparse
from dotenv import load_dotenv
load_dotenv()
# Configuration
SITEMAP_URL = "https://www.walmart.com/sitemap_category.xml"
SITE_NAME = "walmart"
SB_API_KEY = os.getenv("SCRAPINGBEE_API_KEY")
CONCURRENCY_LIMIT = 5 # Adjust as needed
DATA_DIR = "product-data/data"
LOG_FILE = "product-data/logs.csv"
CSV_OUTPUT = "product-data/data.csv"
# Check for API key
if not SB_API_KEY:
logging.error("SCRAPINGBEE_API_KEY is missing. Exiting.")
exit(1)
logging.basicConfig(
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
)
client = ScrapingBeeClient(api_key=SB_API_KEY)
os.makedirs(DATA_DIR, exist_ok=True)
def extract_slug(url):
"""Extract a safe slug from a URL using urlparse."""
parsed = urlparse(url)
slug = parsed.path.rstrip("/").split("/")[-1]
return slug if slug else "default_slug"
def fetch_sitemap_urls():
"""Fetch sitemap URLs and save them to a file."""
logging.info("Fetching sitemap content.")
response = client.get(SITEMAP_URL, params={"render_js": False})
sitemap_data = xmltodict.parse(response.text)
if "urlset" not in sitemap_data or "url" not in sitemap_data["urlset"]:
logging.error("Invalid or empty sitemap structure.")
return []
urls = [urlobj["loc"] for urlobj in sitemap_data["urlset"]["url"]]
urls_file = f"{SITE_NAME}_urls.txt"
with open(urls_file, "w") as f:
f.write("\n".join(urls))
logging.info(f"Sitemap URLs saved to {urls_file}.")
return urls
def scrape_product(url):
"""Scrape a product page, save its JSON data, and return a status log."""
start_time = time.time()
try:
response = client.get(
url,
params={
"premium_proxy": True,
"country_code": "us",
"render_js": False,
"ai_extract_rules": json.dumps(
{
"name": {"description": "Product Name", "type": "list"},
"description": {
"description": "Product Description",
"type": "list",
},
"original_price": {
"description": "Original Price",
"type": "list",
},
"offer_price": {
"description": "Discounted Price",
"type": "list",
},
"link": {"description": "Product URL", "type": "list"},
}
),
},
)
status_code = response.status_code
resolved_url = response.headers.get("spb-resolved-url", url)
if status_code == 200:
try:
cleaned_text = (
response.text.strip().replace("```json", "").replace("```", "")
)
cleaned_data = json.loads(cleaned_text)
slug = extract_slug(url)
with open(f"{DATA_DIR}/{slug}.json", "w") as f:
json.dump(cleaned_data, f, indent=2)
return {
"url": url,
"status_code": status_code,
"resolved_url": resolved_url,
"message": "Success",
}
except json.JSONDecodeError as e:
logging.error(
f"JSON Parsing Error for {url}: {e}. Response snippet: {response.text[:500]}"
)
return {
"url": url,
"status_code": status_code,
"resolved_url": resolved_url,
"message": "JSON Parsing Error",
}
return {
"url": url,
"status_code": status_code,
"resolved_url": resolved_url,
"message": "Scraping Failed",
}
except Exception as e:
return {
"url": url,
"status_code": "Error",
"resolved_url": "",
"message": str(e),
}
finally:
elapsed = time.time() - start_time
iteration_times.append(elapsed)
if len(iteration_times) > 100: # Limit list size
iteration_times.pop(0)
def execute_scraping(urls):
"""Run scraping tasks concurrently and update progress."""
logging.info("Starting concurrent scraping.")
log_entries.clear()
# Demo: Scrape first 100 URLs
with ThreadPoolExecutor(max_workers=CONCURRENCY_LIMIT) as executor:
futures = {executor.submit(scrape_product, url): url for url in urls[:100]}
with tqdm(
total=len(futures), desc="Scraping Progress", dynamic_ncols=True
) as progress_bar:
for future in as_completed(futures):
result = future.result()
log_entries.append(result)
median_time = np.median(iteration_times) if iteration_times else 0
progress_bar.set_postfix(
{
"Median Iter/sec": f"{(1 / median_time) if median_time > 0 else 0:.2f}"
}
)
progress_bar.update(1)
def process_scraped_data():
"""Combine scraped JSON files into a CSV and log any errors."""
json_files = glob.glob(f"{DATA_DIR}/*.json")
df_list, error_files = [], []
logging.info("Processing scraped data into CSV.")
for file in json_files:
try:
with open(file, "r", encoding="utf-8") as f:
data = json.load(f)
if isinstance(data, list):
df_list.append(pd.DataFrame(data))
elif isinstance(data, dict):
df_list.append(pd.DataFrame([data]))
else:
raise ValueError("Unexpected JSON format")
except Exception as e:
logging.error(f"Error reading {file}: {e}")
error_files.append(file)
if df_list:
final_df = pd.concat(df_list, ignore_index=True)
final_df.to_csv(CSV_OUTPUT, index=False, encoding="utf-8")
logging.info(f"Data successfully saved to '{CSV_OUTPUT}'.")
else:
logging.warning("No valid data found to save.")
if error_files:
logging.warning("The following files caused errors:")
for err_file in error_files:
logging.warning(f" - {err_file}")
def save_logs():
"""Save scraping logs to a CSV file."""
logs_df = pd.DataFrame(log_entries)
logs_df.to_csv(LOG_FILE, index=False, encoding="utf-8")
logging.info(f"Logs saved to '{LOG_FILE}'.")
if __name__ == "__main__":
log_entries = []
iteration_times = [] # Track request durations
sitemap_urls = fetch_sitemap_urls()
if sitemap_urls:
execute_scraping(sitemap_urls)
process_scraped_data()
save_logs()
logging.info("Script execution completed.")
else:
logging.error("No URLs found. Exiting.")
This script:
- Fetches Walmart's sitemap and extracts product URLs.
- Scrapes each product page using ScrapingBee.
- Stores structured data in JSON files.
- Processes the data into a final CSV.
- Saves logs for debugging.
With this setup, you can efficiently scrape thousands of product pages! To run it, simply call:
poetry run python link_finder\main.py
Great job!
What if there's no sitemap on the website?
Sometimes, you might stumble upon a website that doesn't have a sitemap (although this is quite uncommon nowadays). But don't worry, there's still a workaround! Here's what you can do:
Instead of relying on a sitemap, we can scan the main page of the website. By doing this, we can identify all the internal links present there. We then add these links to a queue, visit each one, and repeat the process. Once we've explored all the links, we've effectively mapped out the entire website.
While this method isn't foolproof (some pages might not be linked to from anywhere), it's still a pretty robust solution. If you want to dive deeper into this technique, we have another tutorial on our website that covers it in more detail.
The code snippet below provides a simple solution using basic libraries:
from urllib.parse import urljoin # Importing module for URL manipulation
import requests # Importing module for sending HTTP requests
from bs4 import BeautifulSoup # Importing module for web scraping
class Crawler:
def __init__(self, urls=[]):
"""
Constructor for the Crawler class.
"""
self.visited_urls = [] # List to store visited URLs
self.urls_to_visit = urls # List to store URLs yet to be visited
def download_url(self, url):
"""
Function to download the content of a webpage given its URL.
"""
return requests.get(url).text # Sending a GET request to the URL and returning the HTML content
def get_linked_urls(self, url, html):
"""
Function to extract linked URLs from the HTML content of a webpage.
"""
soup = BeautifulSoup(html, 'html.parser') # Creating a BeautifulSoup object
for link in soup.find_all('a'): # Finding all <a> tags in the HTML
path = link.get('href') # Getting the 'href' attribute of the <a> tag
if path and path.startswith('/'): # Checking if the URL is relative
path = urljoin(url, path) # Resolving the relative URL
yield path # Yielding the resolved URL
def add_url_to_visit(self, url):
"""
Function to add a URL to the list of URLs to visit if it has not been visited before.
"""
if url not in self.visited_urls and url not in self.urls_to_visit: # Checking if the URL is not already visited or in the list of URLs to visit
self.urls_to_visit.append(url) # Adding the URL to the list of URLs to visit
def crawl(self, url):
"""
Function to crawl a webpage by downloading its content and extracting linked URLs.
"""
html = self.download_url(url) # Downloading the content of the webpage
for url in self.get_linked_urls(url, html): # Iterating through linked URLs found in the webpage
self.add_url_to_visit(url) # Adding each linked URL to the list of URLs to visit
def run(self):
"""
Function to start the crawling process.
"""
while self.urls_to_visit: # Loop until there are URLs to visit
url = self.urls_to_visit.pop(0) # Get the next URL to visit from the list
try:
self.crawl(url) # Crawling the webpage
except Exception:
print(f'Failed to crawl: {url}') # Handling exceptions
finally:
self.visited_urls.append(url) # Adding the visited URL to the list of visited URLs
if __name__ == '__main__':
Crawler(urls=['https://www.imdb.com/']).run() # Creating an instance of the Crawler class and starting the crawling process with IMDb's homepage as the starting URL
Here's how it works:
- We keep track of the URLs we need to visit in an array called
urls_to_visit. - We identify all the hrefs on the page.
- If a URL hasn't been visited yet, we add it to the array.
- We continue running the script until there are no more URLs left to visit.
This code serves as a great starting point. However, if you're after a more robust solution, please refer to our tutorial on Scrapy.
Automating URL discovery with no-code tools
If you prefer to skip coding altogether, platforms like Make (Integromat) or n8n let you build automated workflows that collect URLs for you. This is especially handy when you want to find all pages on a website online, check all website pages for updates, or simply view all website pages inside a central place like Google Sheets.
How a no-code URL discovery flow works
A typical Make or n8n scenario might look like this:
Google Search module You start by triggering a search such as
site:example.com. The module retrieves a list of indexed pages. While it won't capture everything, it's a quick way to gather highly visible URLs without manual querying.HTTP / Fetch module for sitemap.xml Next, you add a module that fetches
https://example.com/sitemap.xml.
Most sitemaps are straightforward XML files, and both Make and n8n offer tools to parse XML into structured data.
From here, you can extract<loc>nodes and feed all the URLs into your workflow.Filters and Transformers You can add filters to:
- exclude URLs containing parameters,
- only keep HTML pages,
- remove duplicates,
- or ignore staging/test routes.
These steps help clean the data before saving it.
Google Sheets module Finally, direct the parsed URLs into a Sheet. This gives you:
- a live list of all discovered pages,
- easy sorting and filtering,
- a simple dashboard for team access.
Once the scenario is active, you can schedule it daily or weekly, so your URL list stays fresh without you doing anything.
When no-code tools shine — and when they don't
Make and n8n are great when:
- you need results fast,
- the site is publicly accessible,
- the sitemap is clean and not behind protection,
- and your goal is a lightweight monitoring workflow.
But no-code solutions can struggle when:
- the sitemap requires JavaScript rendering,
- the site uses dynamic routing,
- there are anti-bot protections,
- or you need to crawl thousands of pages efficiently.
This is where programmatic solutions or dedicated APIs come in. ScrapingBee's no-code integration for Make bridges that gap: you can stay in a no-code environment while still benefiting from a full web scraping engine that handles JavaScript rendering, blocked requests, and large sites.
ScrapingBee: Fetching and processing URLs at scale
When you need to move beyond small site checks and start working at real scale, ScrapingBee becomes the heavy-duty option built for serious crawling. It's designed for large batches of URL discovery and processing, especially when a site uses JavaScript, rate limits aggressively, or actively blocks scrapers.
ScrapingBee handles the hard parts automatically:
- Automatic proxy rotation to avoid IP blocking
- CAPTCHA avoidance so your workflow doesn't get stuck
- Full JavaScript rendering for modern, dynamic sites
- Consistent HTML output that makes parsing far easier
This is the kind of setup you need when crawling thousands of URLs, analyzing entire sitemaps, or even large e-commerce platforms (and yes, use cases like scrape Amazon fall into this category — for that, ScrapingBee provides a dedicated solution).
Example: Extract titles and meta descriptions from every URL in a sitemap
Let's say you want to take a sitemap, parse all URLs, and extract the page title and meta description for each page. Here's how that looks using ScrapingBee's API.
Python example
import requests
from bs4 import BeautifulSoup
import xml.etree.ElementTree as ET
from concurrent.futures import ThreadPoolExecutor, as_completed
API_KEY = "YOUR_API_KEY"
SITEMAP_URL = "https://example.com/sitemap.xml"
def fetch_sitemap_urls(sitemap_url: str):
"""Fetch and parse sitemap XML, returning a list of URLs."""
resp = requests.get(sitemap_url, timeout=30)
resp.raise_for_status()
root = ET.fromstring(resp.text)
# Namespace-aware extraction of <loc> elements
ns = {"sm": "http://www.sitemaps.org/schemas/sitemap/0.9"}
return [loc.text for loc in root.findall(".//sm:loc", ns)]
def fetch_page_data(url: str):
"""Fetch a single page via ScrapingBee and extract basic metadata."""
try:
response = requests.get(
"https://app.scrapingbee.com/api/v1/",
params={
"api_key": API_KEY,
"url": url,
"render_js": "true",
},
timeout=60,
)
response.raise_for_status()
except requests.RequestException as e:
# You can log this instead of printing in real code
print(f"Error fetching {url}: {e}")
return {"url": url, "title": "", "description": ""}
soup = BeautifulSoup(response.text, "html.parser")
title = soup.title.string.strip() if soup.title and soup.title.string else ""
meta_desc = soup.find("meta", attrs={"name": "description"})
description = meta_desc.get("content", "").strip() if meta_desc else ""
return {"url": url, "title": title, "description": description}
def main():
urls = fetch_sitemap_urls(SITEMAP_URL)
print(f"Found {len(urls)} URLs in sitemap")
# Tune this based on your plan / politeness
max_workers = 8
results = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_url = {executor.submit(fetch_page_data, url): url for url in urls}
for future in as_completed(future_to_url):
data = future.result()
results.append(data)
print(data)
# At this point `results` contains all the URL metadata
# You could write to CSV/JSON here if you want
if __name__ == "__main__":
main()
Node.js example
import { parseStringPromise } from "xml2js";
import * as cheerio from "cheerio";
const API_KEY = process.env.SCRAPINGBEE_API_KEY || "YOUR_API_KEY";
const SITEMAP_URL = "https://example.com/sitemap.xml";
const CONCURRENCY = 5; // how many pages to fetch in parallel
async function fetchSitemap(url = SITEMAP_URL) {
const res = await fetch(url);
if (!res.ok) {
throw new Error(`Failed to fetch sitemap: ${res.status} ${res.statusText}`);
}
const xml = await res.text();
const parsed = await parseStringPromise(xml);
// Basic sitemap.xml shape: <urlset><url><loc>...</loc></url></urlset>
const entries = parsed?.urlset?.url || [];
return entries.map((entry) => entry.loc[0]).filter(Boolean);
}
async function fetchPageData(url) {
const apiURL = `https://app.scrapingbee.com/api/v1/?api_key=${API_KEY}&url=${encodeURIComponent(
url
)}&render_js=true`;
const res = await fetch(apiURL);
if (!res.ok) {
console.error(`Failed to fetch ${url}: ${res.status} ${res.statusText}`);
return null;
}
const html = await res.text();
const $ = cheerio.load(html);
return {
url,
title: $("title").text().trim() || "",
description: $('meta[name="description"]').attr("content")?.trim() || ""
};
}
// simple concurrency helper
async function mapWithConcurrency(items, limit, mapper) {
const results = [];
let index = 0;
async function worker() {
while (index < items.length) {
const i = index++;
try {
results[i] = await mapper(items[i]);
} catch (err) {
console.error(`Error processing item ${items[i]}:`, err);
results[i] = null;
}
}
}
const workers = Array.from({ length: limit }, () => worker());
await Promise.all(workers);
return results;
}
const run = async () => {
const urls = await fetchSitemap();
console.log(`Found ${urls.length} URLs in sitemap`);
const data = await mapWithConcurrency(urls, CONCURRENCY, fetchPageData);
// filter out failed pages
const cleaned = data.filter(Boolean);
console.log(cleaned);
};
run().catch((err) => {
console.error("Fatal error:", err);
process.exit(1);
});
Why use ScrapingBee for large-scale URL processing?
Programmatic crawlers often break down when:
- IPs get blocked
- CAPTCHAs appear
- JS-heavy pages load partial content
- The site rate-limits aggressively
- You need stable performance over thousands of pages
ScrapingBee abstracts all of that away, giving you a clean, reliable HTML snapshot every time. Whether you're mapping a huge domain, analyzing SEO signals, or building a crawler for something more complex, the API keeps your workflow stable and scalable.
What to do once you've found all the URLs
So, you've gathered a whole bunch of URLs — what's next? The answer depends on your goals, but having a full URL list opens the door to a ton of practical and powerful workflows. Here are some of the most common things you can do once you've mapped out an entire domain:
- Scrape structured data (products, articles, reviews, FAQs, etc.)
- Audit SEO elements like titles, meta descriptions, headings, and internal linking
- Check for broken pages by scanning status codes across the full URL list
- Generate screenshots of pages for QA, design review, or archiving
- Monitor content changes across important URLs for research or competitive analysis
- Perform accessibility or performance audits in bulk
- Build datasets for machine learning, LLM fine-tuning, or analytics
- Detect duplicate content or thin pages
- Prepare for a site migration or redesign with a complete inventory
- Feed URLs into automation tools to trigger further workflows (emails, alerts, reports, etc.)
If scraping data from these pages is your end goal, here are some detailed guides that walk you through the process from different angles:
- How to web scrape data from any website — quick start code to get you up and running mining the internet for data.
- The Best Web Scraping Tools for 2025 — discover the top tools that can empower your web scraping projects.
- Web Scraping with Python: Everything you need to know — master the art of web scraping efficiently using Python.
- Easy web scraping with Scrapy — a guide to leveraging Scrapy for Python-powered web scraping.
- Web Scraping without getting blocked — strategies to scrape the web while dodging blocks and bans.
- Web crawling with Python — step-by-step instructions on building a Python crawler from the ground up.
- Web Scraping with JavaScript and NodeJS — learn how to implement web scraping using JavaScript and NodeJS.
Finally, you can always explore the ScrapingBee documentation for deeper capabilities:
https://www.scrapingbee.com/documentation/
ScrapingBee helps you avoid the messy parts of scaling your scraping pipeline — no juggling proxies, no dealing with CAPTCHAs, no managing headless browsers, and no debugging JavaScript rendering quirks. Focus on the insights you want from the URLs you collected, and let the API handle the heavy lifting behind the scenes.
Choosing the right method
With so many ways to discover URLs, the best approach depends on what you're trying to accomplish. Here's a simple decision framework to help you pick the right method — whether you need to find all subpages of a website or fully find all pages on a domain.
If you need a quick check
Use Google Search operators.
They're fast, free, and great for a quick sense of what's indexed. Perfect for light research or grabbing a small set of URLs quickly.
If you're doing an SEO analysis
Use ScreamingFrog or another SEO spider.
Ideal for metadata audits, link structure checks, canonicals, redirects, and everything else SEO-related. Just keep in mind the free versions have crawl limits.
If you want a full site mapping
Use Python + ScrapingBee.
Fetch sitemaps, crawl URLs, extract content or metadata, and customize the workflow however you want. More flexibility than GUI tools and better for large or dynamic sites.
If you need a scalable data pipeline
Use the ScrapingBee API.
This is the go-to option for big jobs: proxy rotation, CAPTCHA handling, JavaScript rendering, and consistent HTML responses. Ideal for automation, repetitive crawls, and large datasets that need stable processing.
Each method has its strengths, so pick the one that matches your goals, scale, and technical comfort level.
Ready to find and scrape every page?
If you're ready to put everything into action — from using a scraping api to automating workflows that get all urls on a website — now's the perfect time to try ScrapingBee for yourself. You get 1,000 free credits, no commitment required, and you can start crawling, rendering JavaScript, and extracting data in minutes.
Conclusion
Today we've unpacked multiple methods to scrape a list of URLs so you can extract the data from them. Mastering this task can set you up for web scraping success and set you off on the right foot, so spending the time to make sure you've got this right is key.
Thank you so much for joining me on this journey. Wishing you all the best with your scraping adventures. Happy data hunting!
FAQs – Finding all URLs on a website
What is the easiest way to find all pages on a website?
For a quick, no-setup method, use Google's site: operator. It shows indexed pages instantly, though not always comprehensively. For full accuracy, combine it with sitemap checks and a crawler like ScreamingFrog or ScrapingBee.
Can I see all pages on a website without coding?
Yes. Tools like ScreamingFrog, Ahrefs Site Audit, Semrush, Make, and n8n let you view all pages visually without writing any code. Just enter the domain, start a crawl, and export the results.
How do I use Google to find all links on a domain?
Use operators like:
site:example.comsite:example.com inurl:blogsite:example.com intitle:guide
Google's Search Operators page provides official documentation.
What's the best tool to crawl all pages of a website?
- For SEO work: ScreamingFrog.
- For cloud-scale crawling or JS-heavy sites: ScrapingBee.
- For full automation or pipelines: Python + ScrapingBee API.
- Open-source users can also explore crawlers such as scrapy/scrapy.
How can I extract all website URLs into Excel or CSV?
Any crawler (ScreamingFrog, Ahrefs, Semrush, Python scripts, ScrapingBee) can export URLs to CSV. Once exported, simply open the CSV in Excel or Google Sheets. Scrapy and Python's pandas library make automated exports easy.
What if a website blocks crawlers – how can I still get URLs?
Use a scraping service with proxy rotation, CAPTCHA handling, and JS rendering. ScrapingBee handles these automatically and can retrieve URLs even from heavily protected sites. For dynamic rendering, consult the ScrapingBee docs.

Ilya is an IT tutor and author, web developer, and ex-Microsoft/Cisco specialist. His primary programming languages are Ruby, JavaScript, Python, and Elixir. He enjoys coding, teaching people and learning new things. In his free time he writes educational posts, participates in OpenSource projects, tweets, goes in for sports and plays music.

